
Incoming CS Ph.D. Student
University of Wisconsin–Madison
I am an 4th year undergraduate researcher in the Department of Computer Science at the University of Virginia, advised by Prof. Kevin Skadron, where I work on modernizing the Rodinia Benchmark Suite.
Previously, I conducted GPU performance and optimization research on LLM-driven CUDA optimization and MLPerf benchmarking at Insight Lab, and earlier worked on GPU-accelerated molecular dynamics simulations and machine learning for materials modeling with Prof. Keivan Esfarjani.
As Moore's Law approaches its physical limits and transistor scaling slows, future performance gains must come from architectural innovation - by squeezing more useful work from every transistor on the die.
This idea has drawn me toward parallel computing and hardware acceleration and motivates me to pursue a Ph.D. in Computer Science at University of Wisconsin–Madison in the upcoming Fall 2026, where I will focus on GPU architecture and benchmarking.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 University of Wisconsin–MadisonSchool of Computer, Data & Information SciencesPh.D. Student in Computer ScienceFall 2026 – Present
University of Wisconsin–MadisonSchool of Computer, Data & Information SciencesPh.D. Student in Computer ScienceFall 2026 – Present -
 University of VirginiaSchool of Engineering and Applied SciencesB.S. in Computer Science and Minor in Applied Mathematics — GPA 3.98 / 4.002022 – 2026
University of VirginiaSchool of Engineering and Applied SciencesB.S. in Computer Science and Minor in Applied Mathematics — GPA 3.98 / 4.002022 – 2026
Honors & Awards
-
UVA Computer Science Summer Research Fellowship2025
-
Dean's Research Scholarship (UVA Engineering)2024
-
UVA Engineering Dean's List — all semesters—
Research Interests
- GPU Architecture & ML Systems
- Workload Characterization & Performance Benchmarking
- Parallel & Heterogeneous Computing
News
I have accepted my offer to join the Ph.D. program in Computer Science at the University of Wisconsin–Madison in Fall 2026.
Received UVA Summer Research Fellowship and joined Prof. Kevin Skadron’s lab to work on Rodinia Benchmark Suite.
New paper on Neuroevolution ML potentials for entropy-stabilized oxides published in Journal of Applied Physics.
Run print("Hello, World") for the first time in UVA CS 1110 class and thought this is kinda cool.
Selected Publications (view all )
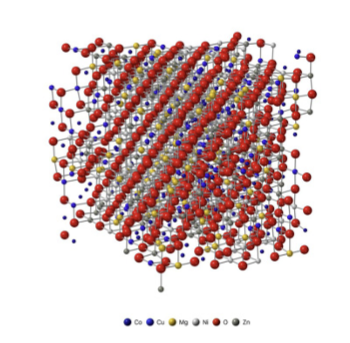
Effect of stoichiometry on thermodynamic and thermal transport properties of entropy-stabilized oxide MgCoNiCuZnO₅
B. Timalsina, H. G. Nguyen, K. Esfarjani
Journal of Applied Physics
Investigates how stoichiometry affects thermodynamic and thermal transport properties of entropy-stabilized oxide MgCoNiCuZnO₅ (J14) using computational methods.
Effect of stoichiometry on thermodynamic and thermal transport properties of entropy-stabilized oxide MgCoNiCuZnO₅
B. Timalsina, H. G. Nguyen, K. Esfarjani
Journal of Applied Physics
Investigates how stoichiometry affects thermodynamic and thermal transport properties of entropy-stabilized oxide MgCoNiCuZnO₅ (J14) using computational methods.
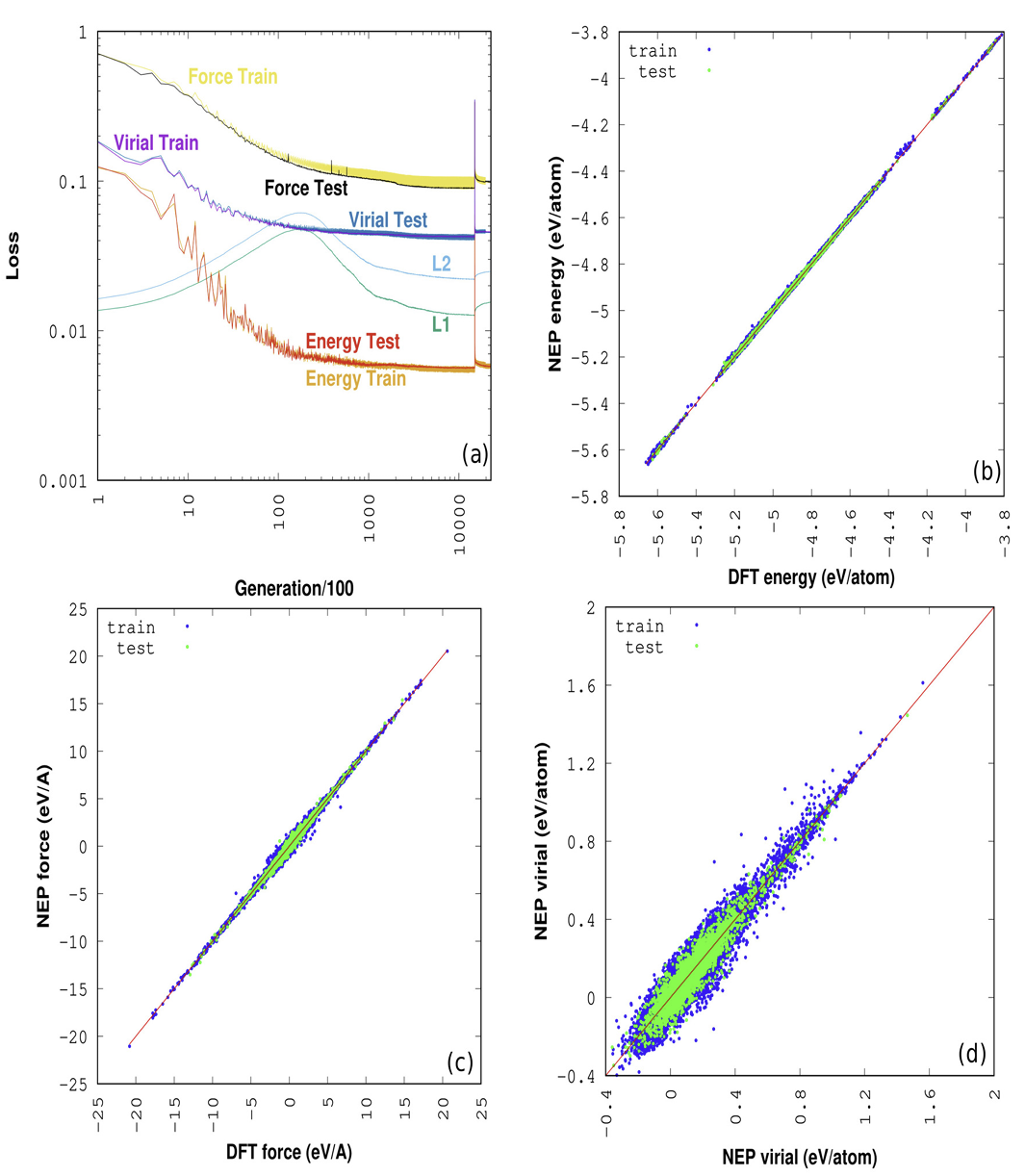
Neuroevolution Machine Learning Potential for High-Temperature Deformation Studies of Entropy-Stabilized Oxide MgNiCoCuZnO₅
B. Timalsina, H. G. Nguyen, K. Esfarjani
Journal of Applied Physics
Development of a neuroevolution machine learning potential (NEP) for entropy-stabilized oxide MgNiCoCuZnO₅ (J14) to explore its lattice distortion, elastic properties, and thermal conductivity across a wide temperature range. The NEP potential demonstrates high accuracy compared to density functional theory (DFT) calculations and experimental data.
Neuroevolution Machine Learning Potential for High-Temperature Deformation Studies of Entropy-Stabilized Oxide MgNiCoCuZnO₅
B. Timalsina, H. G. Nguyen, K. Esfarjani
Journal of Applied Physics
Development of a neuroevolution machine learning potential (NEP) for entropy-stabilized oxide MgNiCoCuZnO₅ (J14) to explore its lattice distortion, elastic properties, and thermal conductivity across a wide temperature range. The NEP potential demonstrates high accuracy compared to density functional theory (DFT) calculations and experimental data.
Selected Projects (view all )
Rodinia v4.0: Modernizing Benchmark Design and Datasets for Emerging GPU Architectures
Prof. Kevin Skadron, LAVA Lab · June 2025 – Present
UVA Undergraduate Research Symposium, Apr 2026 (poster)
Modernizing Rodinia for CUDA 12+, larger datasets, and emerging GPU features (e.g., Tensor Cores, cooperative groups, multi-GPU), with a focus on reproducible benchmarking and microarchitectural analysis using NVIDIA Nsight Tools and GPGPU-Sim.
Rodinia v4.0: Modernizing Benchmark Design and Datasets for Emerging GPU Architectures
Prof. Kevin Skadron, LAVA Lab · June 2025 – Present
UVA Undergraduate Research Symposium, Apr 2026 (poster)
Modernizing Rodinia for CUDA 12+, larger datasets, and emerging GPU features (e.g., Tensor Cores, cooperative groups, multi-GPU), with a focus on reproducible benchmarking and microarchitectural analysis using NVIDIA Nsight Tools and GPGPU-Sim.