Research interests
My research interests lie in GPU architecture, benchmark-driven performance evaluation, and memory systems, with particular expertise in CUDA programming, architectural simulation (GPGPU-Sim), and characterizing workload behavior across GPU generations. In particular, I am interested in understanding where GPU performance is lost in real workloads and designing architectures and benchmarks that expose and close those gaps.
Research Projects
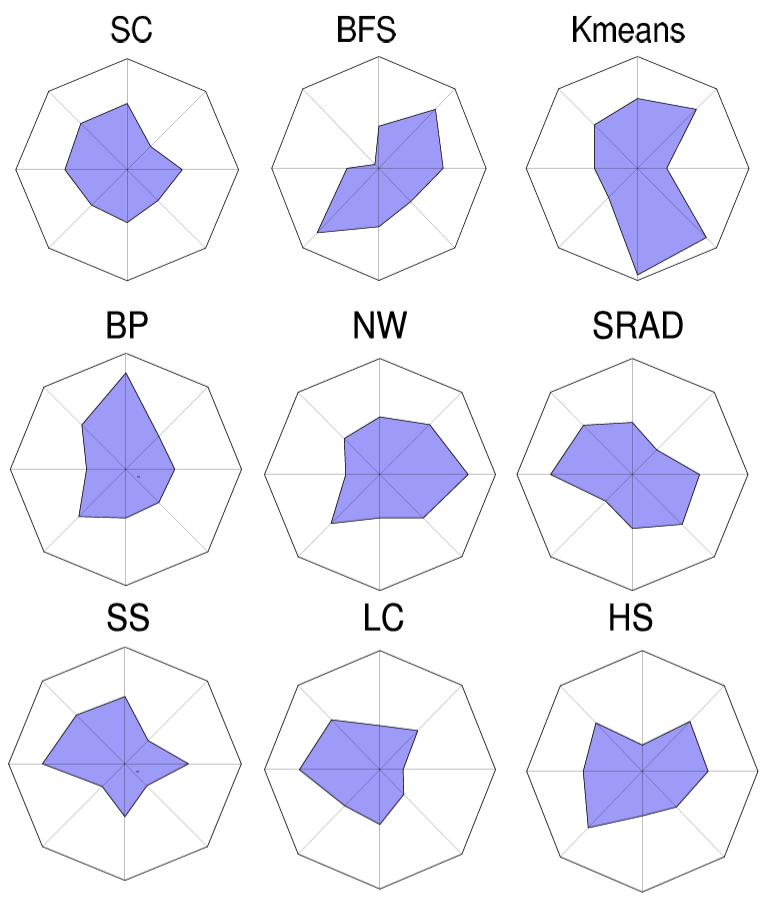
Rodinia v4.0: Modernizing Benchmark Design and Datasets for Emerging GPU Architectures
Prof. Kevin Skadron, LAVA Lab · June 2025 – Present
UVA Undergraduate Research Symposium, Apr 2026 (poster)
Modernizing Rodinia for CUDA 12+, larger datasets, and emerging GPU features (e.g., Tensor Cores, cooperative groups, multi-GPU), with a focus on reproducible benchmarking and microarchitectural analysis using NVIDIA Nsight Tools and GPGPU-Sim.
Rodinia v4.0: Modernizing Benchmark Design and Datasets for Emerging GPU Architectures
Prof. Kevin Skadron, LAVA Lab · June 2025 – Present
UVA Undergraduate Research Symposium, Apr 2026 (poster)
Modernizing Rodinia for CUDA 12+, larger datasets, and emerging GPU features (e.g., Tensor Cores, cooperative groups, multi-GPU), with a focus on reproducible benchmarking and microarchitectural analysis using NVIDIA Nsight Tools and GPGPU-Sim.
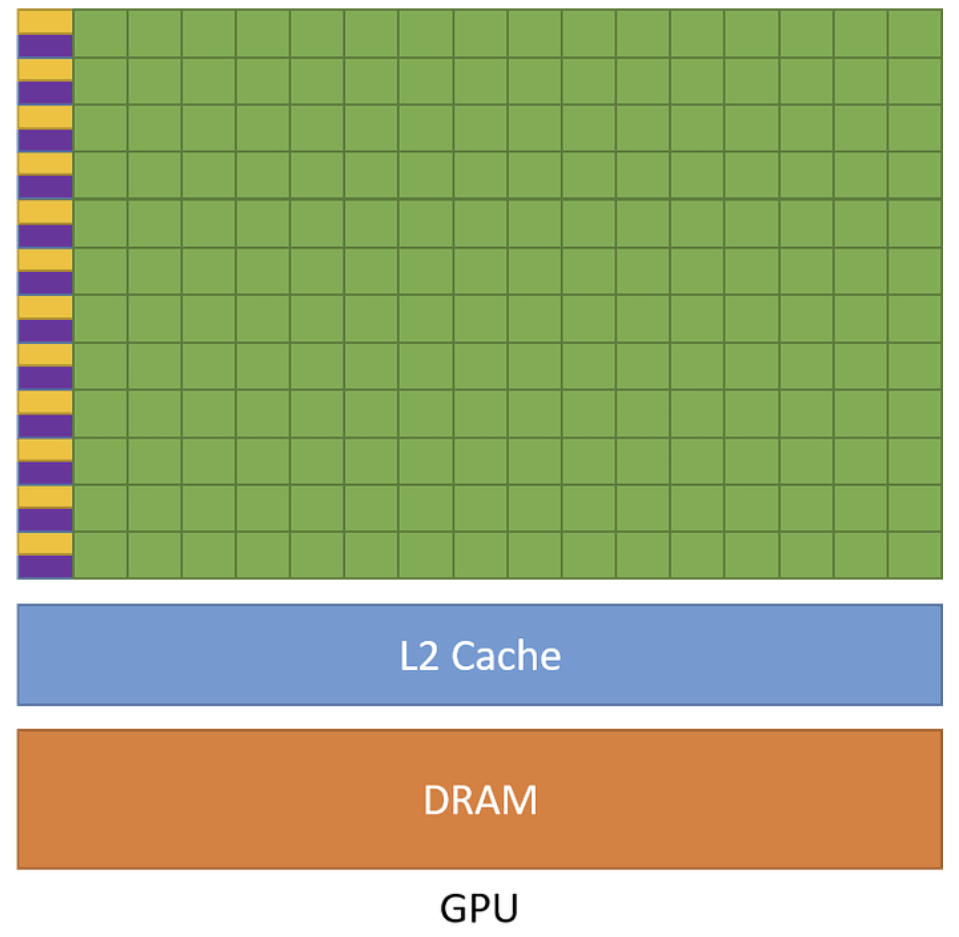
GPU L2 Cache Architecture Exploration with GPGPU-Sim
Prof. Kevin Skadron, LAVA Lab · Feb 2025 – May 2025
Simulated extended L2 cache designs in GPGPU-Sim and modeled area and latency with CACTI, analyzing bandwidth–latency trade-offs, hit rates, and workload sensitivity. Evaluated designs on Rodinia and ML kernels, showing how cache capacity and organization impact performance.
GPU L2 Cache Architecture Exploration with GPGPU-Sim
Prof. Kevin Skadron, LAVA Lab · Feb 2025 – May 2025
Simulated extended L2 cache designs in GPGPU-Sim and modeled area and latency with CACTI, analyzing bandwidth–latency trade-offs, hit rates, and workload sensitivity. Evaluated designs on Rodinia and ML kernels, showing how cache capacity and organization impact performance.
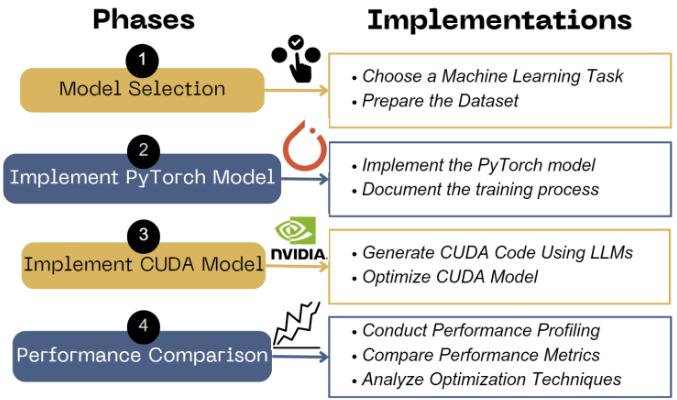
LLM-Driven CUDA Code Optimization: A Comparative Study with PyTorch
Insight Lab · Dean's Research Scholarship · Aug 2023 – Mar 2025
UVA Engineering Research Expo, Nov 2024 (poster)
Developed an LLM-assisted CUDA optimization pipeline, benchmarked against PyTorch on H100/A100 GPUs, and stress-tested large models (ResNet-50, BERT) using RAPIDS (cuML, cuDF, TensorRT).
LLM-Driven CUDA Code Optimization: A Comparative Study with PyTorch
Insight Lab · Dean's Research Scholarship · Aug 2023 – Mar 2025
UVA Engineering Research Expo, Nov 2024 (poster)
Developed an LLM-assisted CUDA optimization pipeline, benchmarked against PyTorch on H100/A100 GPUs, and stress-tested large models (ResNet-50, BERT) using RAPIDS (cuML, cuDF, TensorRT).

Profiling GPU Performance Across MLCommons Tools
Aug 2024 – Dec 2024
Reproduced MLPerf v4.0 ResNet-50 training on UVA GPU servers, analyzed throughput bottlenecks, optimized multi-GPU NVLink scaling with mixed-precision Tensor Cores and XLA, and compared MLPerf variants (training/inference vs Tiny).
Profiling GPU Performance Across MLCommons Tools
Aug 2024 – Dec 2024
Reproduced MLPerf v4.0 ResNet-50 training on UVA GPU servers, analyzed throughput bottlenecks, optimized multi-GPU NVLink scaling with mixed-precision Tensor Cores and XLA, and compared MLPerf variants (training/inference vs Tiny).
GPU-Accelerated Molecular Dynamics & NEP Modeling
Prof. Keivan Esfarjani, ELM Group · Apr 2023 – Mar 2025
Journal of Applied Physics (JAP) '24 and '26
Built a GPU-based MD workflow using GPUMD and neuroevolution potentials for entropy-stabilized oxides; automated SLURM simulations, improved NEP training accuracy, and analyzed thermal trends.
GPU-Accelerated Molecular Dynamics & NEP Modeling
Prof. Keivan Esfarjani, ELM Group · Apr 2023 – Mar 2025
Journal of Applied Physics (JAP) '24 and '26
Built a GPU-based MD workflow using GPUMD and neuroevolution potentials for entropy-stabilized oxides; automated SLURM simulations, improved NEP training accuracy, and analyzed thermal trends.
Selected Hardware Projects
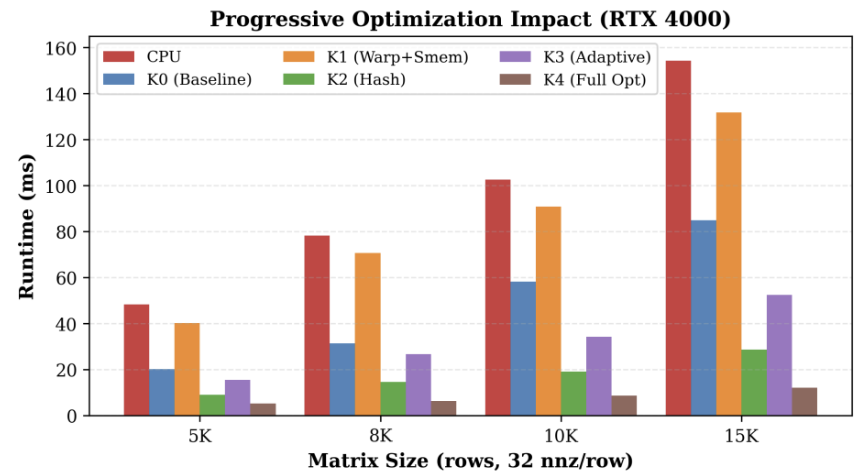
GPU SpMSpM (CS 4444, Fall 2025)
CUDA kernels · Nsight Systems · Nsight Compute
Designed and optimized CUDA kernels for sparse–sparse matrix multiplication (SpMSpM) using shared-memory hashing and dynamic scheduling, achieving strong speedups via improved memory and parallel efficiency.
GPU SpMSpM (CS 4444, Fall 2025)
CUDA kernels · Nsight Systems · Nsight Compute
Designed and optimized CUDA kernels for sparse–sparse matrix multiplication (SpMSpM) using shared-memory hashing and dynamic scheduling, achieving strong speedups via improved memory and parallel efficiency.
CPU/GPU memory & near-data processing (CS 6501, Spring 2025)
Caches · DRAM · PIMeval-PIMbench
Explored CPU/GPU memory hierarchies, cache modeling, DRAM simulation, CUDA programming, and near-data processing using PIMeval-PIMbench.
CPU/GPU memory & near-data processing (CS 6501, Spring 2025)
Caches · DRAM · PIMeval-PIMbench
Explored CPU/GPU memory hierarchies, cache modeling, DRAM simulation, CUDA programming, and near-data processing using PIMeval-PIMbench.